

ゲーム内イベントの予定に合わせたサーバのスケールアウト・インの自動化について【Advent Calendar 12/2】

はじめに
この記事は Colorful Palette アドベントカレンダー 12/2の記事です。
株式会社Colorful Paletteでサーバサイドエンジニアをしているあくびです。現在は「プロジェクトセカイ カラフルステージ! feat. 初音ミク」(以降プロセカ)の開発に関わっています。
プロセカを含め、スマートフォン向けゲームの運用では、ゲーム内のイベント開始時、ガチャ配信時など、アクセス数が急増するタイミングがあります。
プロセカでは特に、イベントの開始時やガチャの開始時、バーチャルライブの開演時などはアクセスが急増します。
オートスケールを設定している場合でも、アクセスの増加に対してサーバのスケールアウトが間に合わず過負荷になってしまい、最終的にはアクセス障害に繋がってしまいます。
そのため、オートスケールとは別に、アクセスが増加する前にサーバをスケールアウトさせておくことで、過負荷になってしまうことを防いでいます。
本記事では、「アクセス急増のタイミングに合わせて事前にサーバをスケールアウトしておく運用」の自動化について取り上げます。
プロセカでは、アプリケーション用のサーバ郡とネットワークアプリケーション用のサーバ群があり、本記事では「ネットワークアプリケーション用のサーバ群」のスケールスケジュール設定の自動化について記載します。
自動化前の運用について
以後、「サーバをスケールイン・アウトさせる特定の日時」をスケールスケジュールと記載します。また、「アクセスの急増が予想されるゲーム内イベントの開催時、バーチャルライブの開演時など」をイベントスケジュールと記載します。
スケールスケジュールの設定フロー
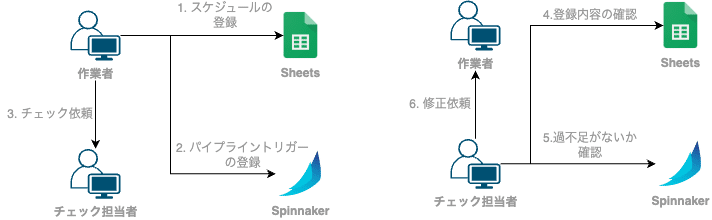
自動化前、イベントスケジュールに合わせたスケールスケジュールの設定は、以下に記載するフローで行っていました。
作業者がスケールスケジュール管理用のスプレッドシートにイベントスケジュールに沿ったスケールスケジュールを記入
作業者がSpinnakerのパイプライントリガーにスケールスケジュールを登録
作業者がダブルチェックを依頼する
チェック担当者がスプレッドシートの記入内容の確認
チェック担当者がSpinnakerのパイプライントリガーの設定内容がスプレッドシートの記入内容に対して過不足がないかチェック
誤った内容があれば、チェック担当者から作業者に修正を依頼する
課題
作業者がイベントスケジュールを目視で確認している、Spinnakerのパイプライントリガーの種類が多い、別種類のバーチャルライブが重なって実施されることがあるなど、様々な要因も相まって、上記の設定フローには以下のような課題がありました。
ダブルチェックをしていても設定ミス、考慮漏れが多々発生していた
設定作業にかなり時間がかかっていた
先 1 ~ 2週間分のスケールスケジュールを登録するのに作業で1時間、チェックで30分ほどはかかっていた
設定を行う日やN週間分設定する、などといった決まりごとが一切なく、設定者が定期的に思い出して設定していた
これらの課題を解決するために、スケールスケジュール設定の自動化を行いました。
自動化について
設計
どのデータをどこに持つか、どのパブリッククラウドのサービスをどう連携させるかなどを考慮しつつ、まずインフラから設計を行いました。
プロセカのインフラでは、アプリケーション用サーバ郡をAWSに構築し、ネットワークアプリケーション用サーバ郡をGoogle Cloudに構築しており、複数のパブリッククラウドにまたがった運用となっています。
そのため、異なるパブリッククラウドへのアクセスに必要な認証情報などを整理しながら設計を進めました。
最終的に落ち着いた初期設計は以下のとおりです。

実装と運用①
インフラの設計が終わり次第、自動設定用システムのコードを実装します。
実装
Google Calendarに予定を流し込むエンドポイント
Spinnakerのパイプライントリガーを設定するエンドポイント
Cloud Schedulerのジョブ設定
毎日10時に発火する、3日後のイベントスケジュールとスケールスケジュールをGoogle Calendarに登録するためのジョブ
毎日10時に発火する、1日後のスケールスケジュールをGoogle CalendarからSpinnakerのパイプライントリガーに登録するためのジョブ
登録されたSpinnakerのパイプライントリガーの内容は、毎日Slackの通知チャンネルに通知され、登録が失敗した際はメンションとともにエラー内容が通知されます。
しばらくはこの状態で運用を行いました。このシステムの運用期間で、システムで詰めきれていなかった部分の明確化を行いました。
参照するマスターデータのバージョンをマスターデータが更新されるタイミングに合わせて手動で切り替えていた
参照するマスターデータを切り替えた後に発生する、登録済みのスケールスケジュールの削除や未設定のスケールスケジュールの挿入をCloud Schedulerのジョブを手動で強制実行することで行っていた
Spinnakerに設定されている過去のパイプライントリガーが残り続ける
Spinnakerのパイプライントリガーをcronで設定しており、このcronでは発火する年を指定しないため、一年後に意図しないタイミングでトリガーが発火する可能性がある
実装と運用②
しばらくの運用期間を経て得られた課題を解消するにあたって、追加で設計と実装を行いました。
インフラ面では、以下の構成となりました。

プロセカでは、マスターデータの反映フローの中に、リリースが確定したマスターデータをS3(上記図のDump Master)にアップロードする工程があります。このタイミングでマスターデータのバージョンが更新が検知できるため、マスターデータのバージョン取得の参照元としています。
追加で実施した実装は以下のとおりです。
S3へのファイルアップロードをフックとした、参照するマスターデータのバージョンの自動変更機能(AWS Lambda)
参照するマスターデータのバージョンが変更されたときに、設定済みのGoogle Calendarの予定とSpinnakerのパイプライントリガーを設定し直す機能(Cloud Run)
毎朝Cloud Schedulerのジョブで登録されるSpinnakerのパイプラインの過去トリガーの削除
上記の対応によって、参照するマスターデータのバージョン変更やSpinnakerのパイプライントリガーの再設定などといった手動フローが完全に撤去されました。
おわりに
私の入社当時が運用期間中でありながらネットワーク通信に関連する基盤を刷新したばかりのタイミングであったため、運用に関連するノウハウが不足していたり、長期運用に目を向けた対策が取られていないという状態でした。
スケールスケジュールの設定作業を引き継いだ当時、「なんだこの複雑な設定は…めっちゃ時間かかるしめっちゃミスりそう…」と思った記憶があります。
実際、ダブルチェックを実施していても設定ミスに繋がることも多く、運用を続けていく上ではかなり大きな問題になっていたと思います。
自動化をしたことで、設定ミスもほぼなくなり、設定ミスが起因となる障害件数もほぼ0件になりました。
エンジニアとして、めんどくさいなぁ、ミスしそうだなぁ、神経使うなぁと思った作業は、自動化できないかという思考に切り替えて、楽をしつつ安定させることに意識を向けていければいいなぁと思っています。
この記事が、少しでも皆様のお役に立つことができれば幸いです。
次回はグラフィックスエンジニアのとぐちさんです!弊社のグラフィックスに関して欠かせない技術力を持ったメンバーなので面白い記事が見られると思います〜!