
EC2インスタンスのオートスケーリンググループを本番導入してみた

はじめまして。
20卒バックエンドエンジニアのhrksです。
弊社では、先日EC2インスタンスを利用したオートスケーリングを導入しました。この記事では導入時に生じた課題や解決策、最終的に実装したアーキテクチャについて説明します。
今回はオートスケーリングとは?といった基本的な概要については説明せず、主に本番導入時に考慮した点と、弊社で実装したアーキテクチャについて説明します。
オートスケーリングの概要については、下記の記事などを参照ください。
Amazon EC2 Auto Scaling とは
対象読者
・オートスケーリングの本番導入を検討中の方
導入のモチベーション
オートスケーリング導入以前は、非オートスケールのEC2インスタンスを固定台数で運用していました。 従来の設計には下記のような難点がありました。
・コスト効率が悪い
- 柔軟な台数変更が難しく、アクセスピークに合わせた台数での運用
・オペレーションが面倒
- ABデプロイ
- インスタンスの入れ替え作業
これらの問題を解決するため、今回はEC2インスタンスのオートスケーリング導入を実施しました。 オートスケーリングを導入することで、下記の状態になることを期待していました。
・コスト効率が良い
- 台数最適化
- オートスケーリング
・オペレーションが楽に
- Blue/Greenデプロイ
- インスタンスの更新機能
- アクセススパイクのための一時的増強の効率化
導入にあたっての課題と対策
オートスケーリング導入にあたり下記の設計上の課題がありました。
・BGデプロイのハンドリング
・ログ退避
・スケーリンググループ内で一意なIDの付与
これらの課題と実施した対策について説明します。
BGデプロイのハンドリング
CodeDeployが提供するBGデプロイ機能は、ALBに対するインスタンスのアタッチ・デタッチ操作をハンドリングしてくれます。 一方、この際にスケール処理が衝突した場合、対象のインスタンスが存在しない or 意図しないインスタンスが存在したりする影響で操作が完了できず、デプロイプロセスがスタックしてしまいます。
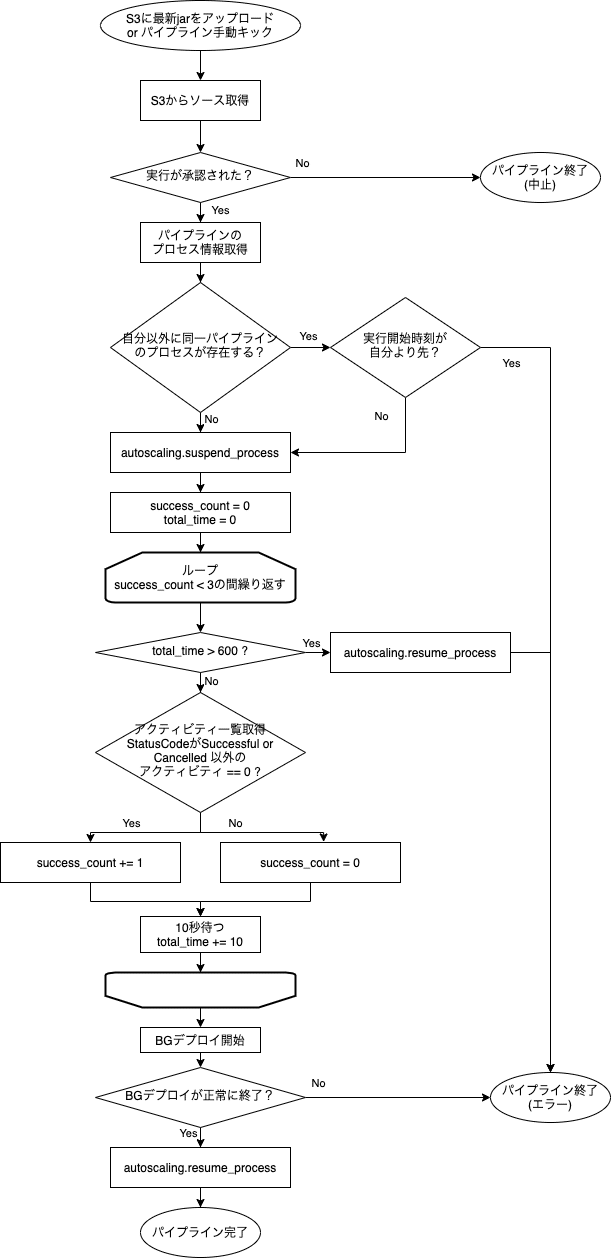
また、BGデプロイが2回同時に実行された場合も不具合が発生する場合があります。 この問題を避けるために、BGデプロイ用のパイプラインをCodePipelineで組んで対策を行いました。
パイプラインでは、デプロイ前に下記2つのバリデーションを行ないデプロイとスケールの排他制御を行なっています。これらのチェックによって、デプロイとスケールの競合によるエラーを回避しています。
1. 同一パイプラインの先行プロセスが存在するか?
2. デプロイ対象のスケーリンググループに進行中のスケールイベントが存在するか?
また、上記のバリデーションに加えてデプロイ前後でスケールイベントの停止と再開を行なっています。 デプロイパイプライン全体のフローチャートが下記になります。
ログ退避
オートスケーリングではスケールポリシーに従ってEC2のインスタンスが自動でスケールインされます。 平常時はKinesis Agent を使用してログを1分間バッファしてから送出していましたが、スケールインの際は能動的にログ退避を行わなければログ欠損の恐れがあります。
この問題に対処するため、当初はLambdaでオートスケーリングのスケールインイベントをフックに自前でログを退避する関数を実装していました。
ただ、この方法だとKinesis Agentで通常時に送出しているログと退避ログとの重複除去を追加で実装する必要があり、数万行のログをチェックする重い処理が必要となってしまいます。
そこでログ送出をKinesis Agentに任せるべく、ALBからデタッチをした後に指定の時間waitする関数を実装しました。デタッチ後に2分 (ALBのdrain timeout 1分 + Kinesis Agentの最大ログバッファ時間 1分) を待つようにしています。
スケーリンググループ内で一意なIDの付与
こちらはサービス特性に紐づくものですが、プロジェクトセカイではユーザIDの生成に Snowflake ライクなIDジェネレータを利用しています。
このIDジェネレータではデータセンタを表すID、そのデータセンタ内でのノードを表すIDを乱数シードとして利用します。 これら2つのIDは1つのEC2インスタンスに紐づいており、インスタンス起動時にグループ内に存在するインスタンスの間でユニークな値を取得する必要があります。
元々はterraformの count.index を利用して採番を行なっていました。 しかし、オートスケーリングを導入するとインスタンスの起動はオートスケーリンググループの仕事になるため、terraformの count 変数を利用できません。 そのため、別の仕組みで採番する必要がありました。
そこで、DBを別途作成し使用中のIDを記録する枠組みを導入しました。 インスタンスの起動時には、EC2のユーザデータからLambda関数を呼び出してDBを参照し空いているIDを取得します。 インスタンスの終了時に、そのインスタンスで使用しているIDをDBから消すようにしました。
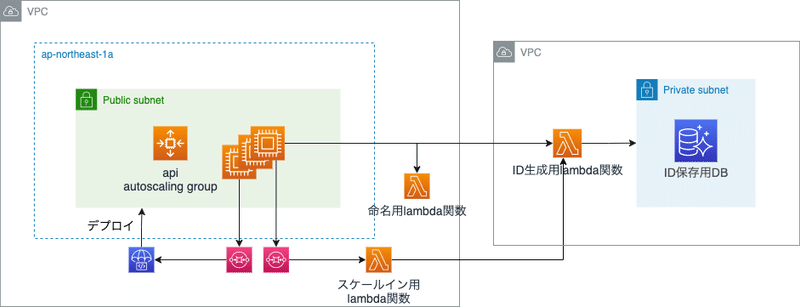
スケールのアーキテクチャ
上述の対策を加えたスケールのアーキテクチャについて説明いたします。 大まかなアーキテクチャ図は下記のようになっています。
スケーリングポリシー
今回、スケールのポリシーは ターゲット追跡スケーリング にてスケーリンググループ内の平均CPU使用率を 60% に維持するよう設定を行いました。 このポリシーでは、スケーリンググループ内のCPU使用率が一定時間設定値を超えるとスケールアウト、一定時間下回るとスケールインを行います。
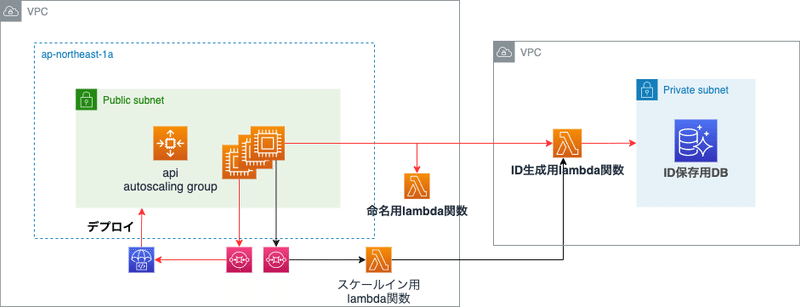
スケールアウト
スケールアウトで使用するコンポーネントは下記の赤線部分になります。
インスタンス起動処理
ほとんどの起動処理をEC2のユーザデータから行なっています。 行っている処理については下記のものがあります。
ユーザデータで行うもの
・各種パッケージのインストール
・Nameタグの割り振り
・スケーリンググループ内で一意なIDの付与
- Lambda関数を呼び出し、環境 (dev、stgなど) とインスタンスIDを元に空いているIDの付与を行ないます。
CodeDeployで行うもの
・最新サーバアプリのデプロイ
- CodeDeployで最後にデプロイされたアプリを新規インスタンスに対してデプロイします。
- CodeDeployでスケーリンググループ対象のBGデプロイグループを作ると、スケールアウトイベントをフックとするデプロイイベントが作成され、新規インスタンスへのデプロイを行ってくれます。
注) 一度BGデプロイが成功していないとイベントが発動されません。
イベントの開始タイミングと所要時間
スケールアウトイベントは、スケーリンググループの平均CPU使用率が60%を超えている状態が3分続くとイベントが発動されます。 現状の設定では、デプロイやヘルスチェックの期間を全て含めると、スケールアウトが発動されてからInServiceなインスタンスができるまでに約5分ほど時間が必要になっています。
この所用時間については、初回ヘルスチェックまでの時間やヘルスチェック間隔に関する設定をチューニングすることで、さらに短縮することが期待できます。
また、ウォームアップ期間 (スケーリンググループのメトリクスに含まれるまでの時間) を5分に設定しているため、 スケールアウトが発動してからさらに次のスケールアウトが発動するまでは、大体10分ほど必要になっています。
スケールアウトされるサーバの台数については、現状の台数とCPU使用率からスケーリンググループが自動的に算出します。
スケールイン
スケールインで使用するコンポーネントは下記の赤線部分になります.
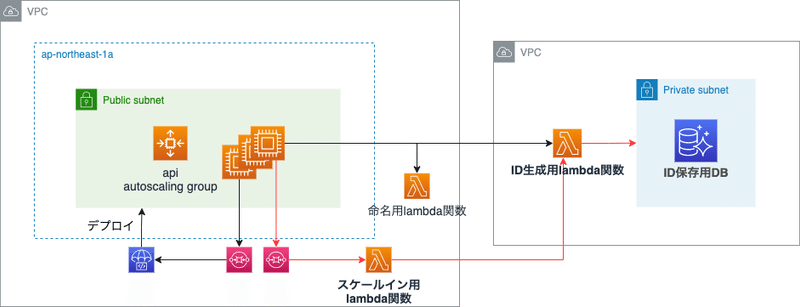
インスタンス終了処理
SQSに通知されるスケールインイベントをフックにLambdaの関数を呼び出して処理しています。
・ログ退避用の待機
- インスタンスをALBからデタッチをし、ログ退避用に120秒間の待機を行います。
・DBに登録したスケーリンググループ内で一意なIDの削除
- 自分のインスタンスIDを持つレコードをDBから削除し、IDの占有状態を解放します。
イベントの開始タイミングと所要時間
スケーリンググループに含まれているインスタンスの平均CPU使用率が54% (設定値の9割) を下回っている状態が15分続くとスケールインが開始されます。 スケールインが完了するまでには3分ほど必要になっており、その大半はログ退避のための待機時間 (2分) です。
また、スケールインが終わってから次のスケールインが発動するまでは1分必要です。 スケールインされるサーバの台数についても、現状の台数とCPU使用率からスケーリンググループが自動的に算出します。
運用してみての所感と今後の展望
オートスケーリンググループを導入することで仕組みが複雑化するため、運用上考慮が必要な箇所は増えてしまいますが、それ以上に恩恵の方が大きいと感じています。
スケールが簡単に行えるためイベント時の負荷対策が非常に楽になりました。平常時のインスタンス台数が半分以下に抑えられたため、コストもその分抑えられています。
また、オートスケーリング用のAPIが潤沢に用意されているため、スケール設定も半自動化できオペレーションもかなり改善ができました。 結論、当初の目的であったコストとオペレーションの効率化は達成でき、健全なインフラに一歩近づけたかなと思います。
一方、更なる効率化に向けて今後以下のことにも取り組んで行きたいと思っています。
・スケールアウトの高速化
- ヘルスチェック、ウォームアップ周りの設定チューニング
- コンテナ化
・オートヒーリングの有効化
・BGデプロイの高速化
最後に、今回紹介できなかった導入時のハマりポイントを列挙しておきます。
・インスタンスの荷重キャパシティを設定しているとBGデプロイが完了できない
・ライフサイクルがうまく完了できなかった場合、complete-lifecycle-action APIで能動的にインスタンスをリタイアさせないとタイムアウト (デフォルト60分) まで待つ
・BGデプロイによってスケーリンググループが生まれ変わるため、terraformの管理が面倒
以上、導入検討中の方の参考になれば幸いです。